
Feature Engineering: preparando dados para aprendizado de máquina

Feature engineering é o termo utilizado para definir um conjunto de técnicas utilizado na criação e manipulação de features (recursos), tendo como objetivo desenvolver um bom modelo de aprendizado de máquina.Você também pode conhecer essa etapa como pré-processamento de dados, embora muitos entendam o feature engineering faça parte dele. Essa é uma das fases mais importantes do processo de construção de um modelo preditivo.
Porém, feature engineering não se trata apenas de selecionar bons recursos para um modelo. Esse processo também abrange a transformação matemática nas features existentes para extrair o máximo potencial dos dados e criação de novas features. Neste artigo vou trazer as técnicas mais utilizadas.
O que é feature engineering?
Praticamente todos os algoritmos de Aprendizado de Máquina possuem entradas e saídas. As entradas são formadas por colunas de dados estruturados, onde cada coluna recebe o nome de feature, também conhecido como variáveis independentes ou atributos. Essas features podem ser palavras, pedaços de informação de uma imagem, etc. Os modelos de aprendizado de máquina utilizam esses recursos para classificar as informações. Por exemplo, sedentarismo e fator hereditário são variáveis independentes para quando se quer prever se alguém vai ter câncer ou não.
As saídas, por sua vez, são chamadas de variáveis dependentes ou classe, e essa é a variável que estamos tentando prever. O nosso resultado pode ser 0 e 1 correspondendo a ‘Não’ e ‘Sim’ respectivamente, que responde a uma pergunta como: “Fulano é bom pagador?” ou a probabilidade de alguém comprar um produto ou não.
Utilizando o conhecimento da área de negócio que estamos analisando, procuramos descobrir quais são as características mais importantes dos dados e, então, os preparamos para entrar em um modelo de aprendizado de máquina. Como já comentamos aqui, quanto maior a correlação entre uma feature e a variável que se quer prever, mais importante essa feature é.
Mas precisamos tomar alguns cuidados. Por exemplo: se uma feature distância é importante e ela está em quilômetros, também podemos considerar inseri-la em metros no modelo. Porém, isso vai fazer com que o modelo considere essa informação como sendo mais relevante do que realmente é, já que ele a recebeu duas vezes. Portanto, o feature engineering não se trata apenas de selecionar boas features, esse processo também abrange a transformação matemática nas features existentes para extrair o máximo potencial dos dados e criação de novas features. Criar novas features a partir das existentes é ainda mais importante quando temos poucos dados, pois modelos que utilizam poucas instâncias tendem a realizar overfiting.
Dizemos que um modelo de aprendizado de máquina está realizando overfitting quando ele aprendeu muito com os dados de teste, e não consegue ter boa assertividade com os dados novos. Por exemplo, pense que você está estudando para uma prova, e você estuda somente se baseando no resumo que lhe foi dado. Então, na hora da prova, aparecem questões diferentes daquelas do teste e provavelmente você não vai saber resolver. A mesma coisa acontece com os modelos de Aprendizado de Máquina. É como se os modelos tivessem “decorado” certas informações e quando algo diferente daquilo aparece, a máquina não sabe o que fazer.
Logo, feature engineering envolve análise de dados, aplicação de regras práticas, bom senso e testes. Inclusive ele e a análise exploratória de dados podem ser realizados em conjunto. O feature engineering geralmente é feito de forma manual, o que o torna um dos gargalos do processo de construção de um modelo de aprendizado de máquina. Vou explicar o porquê: se este processo é realizado manualmente, pode estar suscetível a erros, pois depende da experiência, do conhecimento dos dados e da área de estudo, como também de testes para entender como o modelo está performando com as features escolhidas. Caso não se tenha amplo conhecimento da área em que este algoritmo será aplicado (como medicina ou biologia, por exemplo) é interessante estar apoiado por um especialista.
Por que utilizar feature engineering?
Pense que você vai fazer sua receita favorita. Você vai precisar dos ingredientes, digamos: tomate, alho, carne e macarrão. Então, você coloca tudo dentro da panela: os tomates e o alho inteiros e com casca, a carne crua e a massa com o plástico. Com certeza o resultado final vai passar longe de um macarrão à bolonhesa. Você vai precisar descascar, cortar, cozinhar a carne, retirar a massa do pacote… O mesmo acontece com os recursos: eles precisam ser pré-processados para colocá-los no modelo preditivo e obter um bom resultado final. Seu modelo não vai pegar os dados cheio de valores faltantes, variáveis duplicadas, inconsistências e resolver tudo em um passe de mágica. Não existe mágica.
Outro motivo para se preocupar é que conforme o tempo passa, tendemos a ter mais dados disponíveis, o que torna a seleção de quais desses dados são mais relevantes ainda mais trabalhosa e, ao mesmo tempo, cada vez mais importante, pois vai ser cada vez mais fácil selecionar features erradas em um mar de dados.
Algumas técnicas de feature engineering
Criação de feature
A primeira coisa a se fazer ao começar um processo de feature engineering é entender todas as variáveis preditoras importantes que precisam ser incluídas no modelo. Depois, você deve se fazer as seguintes perguntas: “Eu tenho esses dados?” ,“Consigo criar esses dados?”.
Um dos erros mais comuns é focar nos dados disponíveis ao invés de se questionar quais dados são necessários. Esse equívoco faz com que variáveis essenciais para o negócio sejam deixadas de lado, pois não existem nos dados. Se muitas dessas variáveis essenciais não estiverem disponíveis para processamento, vale voltar para a etapa de coleta. Criar novas features pode trazer à tona informações que são de extrema importância, mas não estavam explícitas nos dados. Por exemplo, podemos ter a data em que alguém começou a usar um serviço mas o que realmente precisamos é apenas do mês para entender se há alguma sazonalidade. A partir da feature data é possível criar uma nova contendo apenas o mês.
Vamos analisar uma base de dados do Kaggle usada para prever o valor de casas na Califórnia.
Primeiramente, fizemos a leitura dos dados csv e transformamos esses dados em um dataframe do Pandas chamado data.
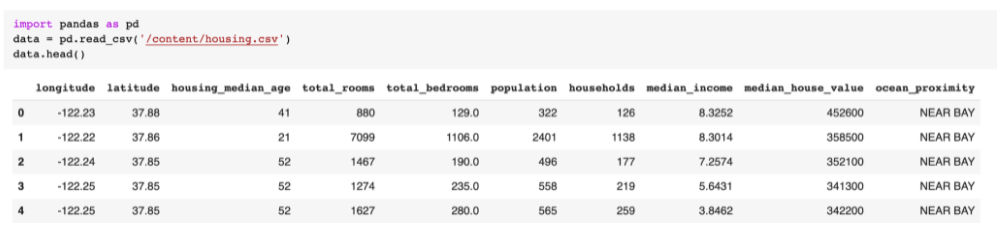
Mesmo sem muito conhecimento sobre preço de casas na Califórnia, imagino que o valor por metro quadrado seja importante, e note que não temos esses dados. Se tivéssemos a metragem da casa, poderíamos construir essa feature fazendo a divisão do preço pelo tamanho da casa em metros.
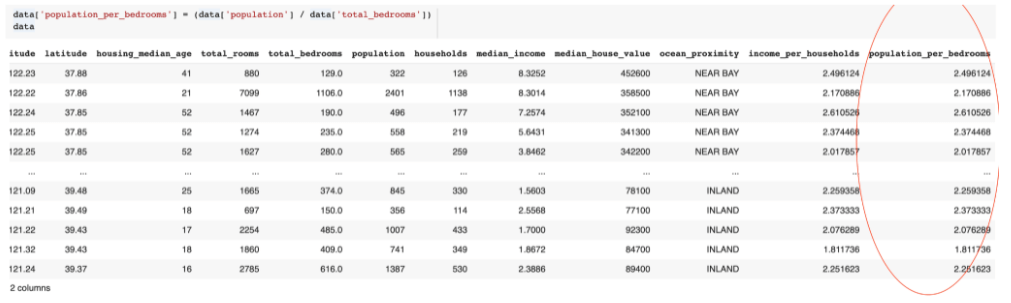
Também podemos criar uma nova feature contendo a divisão de pessoas por quartos nas casas, e a partir disso é possível trabalhar com essa feature, arredondando, fazendo média, etc.
Transformações de features
A transformação de features leva em consideração o tipo de dados e sua compatibilidade com o modelo e também se o tipo da variável passa a maior quantidade de informação possível. Algumas técnicas de transformação mais comuns são:
- ** Missing values**: Valores ausentes na base de dados podem ocorrer por vários motivos, como questões de permissões, erros humanos, erros de código, etc. A maioria dos algoritmos de aprendizado de máquina não aceitam conjuntos de dados com valores ausentes. Há um consenso de que se uma feature tiver mais que 20% dos dados faltantes em sua coluna, é melhor não utilizá-la e entender porque esses valores estão faltando. Caso uma feature tenha até 20% dos valores faltando, preencher esses dados com a média ou a mediana da variável. Quando for um valor categórico preencher com o valor categórico médio. E quando se tem menos de 2% dos dados de uma feature faltando, o mais indicado é deletar esses registros, pois como são poucos, sua base de dados não vai diminuir muito, além de poder causar outros problemas.
Vamos voltar para o nosso exemplo do preço de casas na Califórnia para entender se temos muitos dados faltantes.
Buscamos, então, o somatório de dados faltantes em todo o dataframe.

Encontramos apenas o total de quartos com 207 registros vazios. Mas qual é a porcentagem do total de quartos que está vazio?

Fazendo o cálculo da porcentagem encontramos que aproximadamente 1% do total de quartos está vazio. Temos duas possibilidades, remover essas linhas com os quartos vazios, ou preencher esses dados com o valor da média da coluna total de quartos. Vamos escolher essa segunda opção:
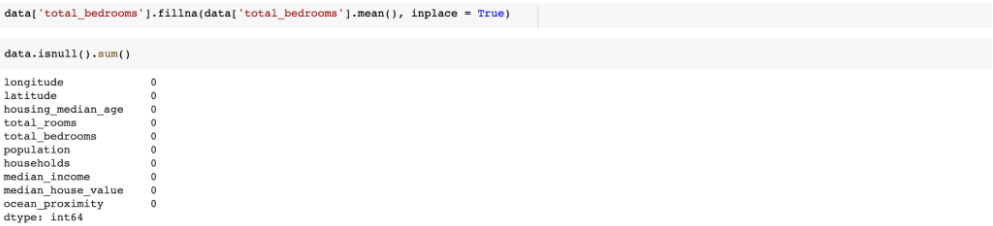
Utilizamos o fillna() do pandas, esse método recebe dois parâmetros: o valor que se está buscando preencher no lugar os dados vazios e o inplace=True que é necessário para realmente alterar o nosso dataframe.
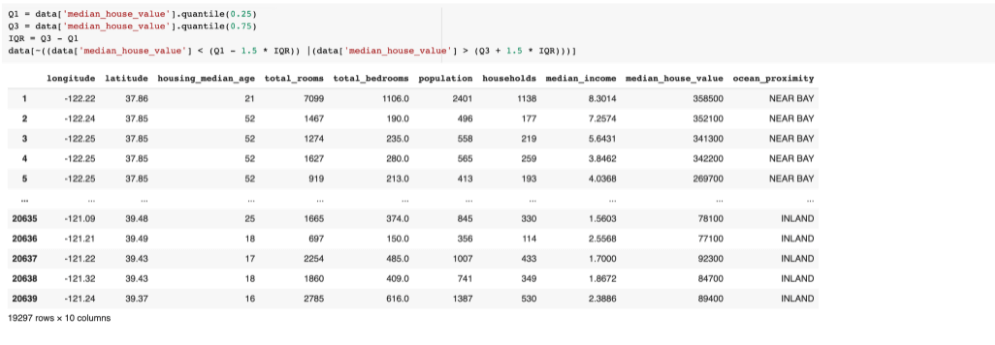
- Manipulação de outliers: Outliers são valores fora do “padrão” encontrados nos dados. Um valor é considerado um outlier quando a diferença dele para a média é maior que x * desvio padrão, ou quando os valores estão abaixo do primeiro quartil (Q1) ou acima do terceiro quartil (Q3) da distribuição de dados. Ao identificar um outlier é sempre identificar o motivo de ter ocorrido, pois ele pode ser uma boa oportunidade de negócio. No entanto, os outliers também podem ser erros no conjunto de dados. Por exemplo: imagine o valor 1971 na coluna ‘idade’, provavelmente esse era o ano de nascimento de alguém e foi inserido de forma errada. Uma forma muito boa de identificar os outliers é através do gráfico boxplot.

No gráfico acima podemos visualizar a distribuição da renda média de famílias dentro de uma casa. O quadrado azul nos mostra a distribuição dos dados entre primeiro quartil (Q1), mediana e terceiro quartil (Q3). Os traços afastados da caixa azul são os valores mínimo e máximo, e os pontos abaixo e acima do mínimo, bem como o máximo são considerados outliers.
Após fazer a análise do porquê desses outliers, veja se você precisar removê-los. Se for o caso, pode fazer dessa forma:
- Binning: Essa técnica é geralmente utilizada em dados numéricos e tem objetivo de separar os dados em conjuntos ou intervalos. Considerando nosso exemplo, poderíamos transformar o preço das casas em categorias como Alto, Médio e Baixo. O binning pode reduzir o desempenho do modelo mas vai evitar bastante overfitting, então é preciso fazer um balanço entre o quanto você vai perder de desempenho versus o quanto você vai reduzir de overfitting. Sem contar que você pode acabar perdendo muita informação nesse processo, então, novamente, é preciso conhecer muito a área de negócios para entender se o binning vai valer a pena.
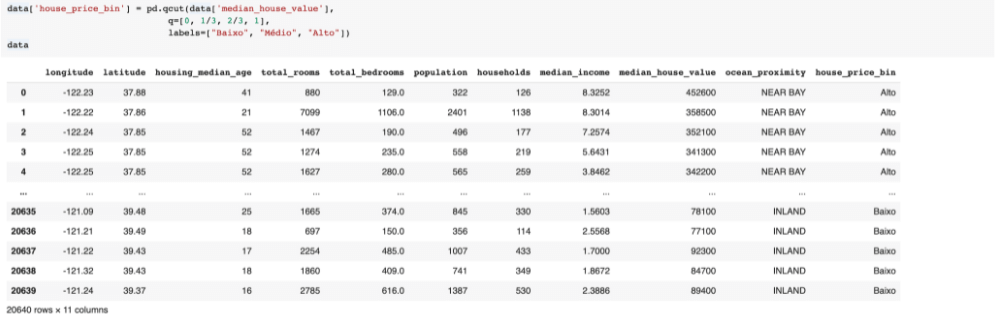
No caso acima, criamos uma nova feature e transformamos dados numéricos em dados categóricos.
- One-hot encoding: O one-hot encoding é usado para transformar variáveis categóricas em colunas e atribuir valores 0 e 1 para os valores dessas colunas. O 0 é usado para quando um registro não possui aquele valor, e 1 para quando ele tem aquele valor. O objetivo do one-hot encoding é deixar os dados mais entendíveis para os algoritmos, já que as máquinas entendem 0’s e 1’s.
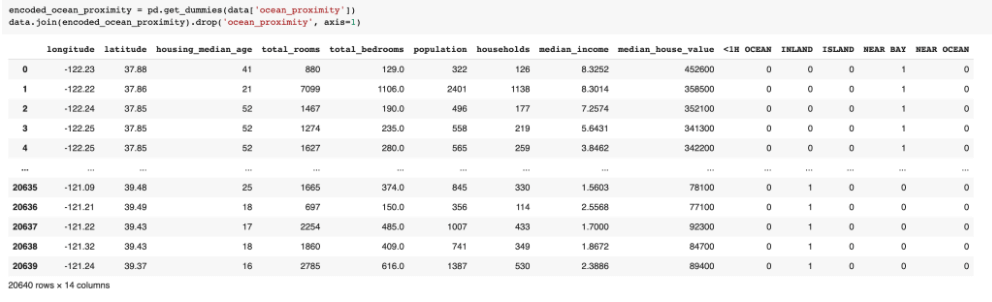
No exemplo alteramos nossa variável de proximidade com o oceano, e todas as opções desta feature viraram uma coluna. Nos registros onde a proximidade com o oceano era próximo da baía (near bay) essa coluna recebeu 1 e as outras opções de proximidade receberam 0.
- Grouping: Podemos realizar o agrupamento de variáveis categóricas e numéricas. No agrupamento numérico são utilizadas funções de média e soma dos casos, e no agrupamento categórico buscamos selecionar o rótulo de maior frequência. O objetivo do agrupamento é juntar linhas que estejam espalhadas e usar esse agrupamento para visualizar informações de média e mediana de outras features em relação a esse agrupamento.

No exemplo acima de agrupamento numérico, reunimos os dados pela coluna proximidade ao oceano e buscamos a média da população de acordo com a distância do oceano.
Seleção de feature
Ao final da transformação das features, é preciso escolher quais delas vão para o modelo, pois às vezes possuímos recursos demais e o modelo de previsão não vai conseguir aguentar todas as variáveis possíveis, ou o tempo de treinamento do modelo vai aumentar muito.
Passar todas as features para o modelo pode fazer ele considerar relações que não existem e, até mesmo, considerar uma feature como mais importante do que ela realmente é. Por exemplo, se você tem uma grande quantidade de dados, algumas coincidências podem ter ocorrido e ficaram guardadas nos dados, e a máquina pode acabar considerando isso como uma regra com baixa correlação.
Essa etapa é um pouco exaustiva e manual, mas vai ser preciso testar várias combinações de features e medir qual gera a maior acurácia do modelo preditivo.
Conclusão
O processo de feature engineering é um dos mais importantes de toda a construção do aprendizado de máquina. Lembrando da metáfora sobre cozinhar: quanto melhor forem os ingredientes, melhor vai ser seu resultado final. A mesma coisa acontece aqui, quanto melhor forem seus dados de entrada, melhor vai ser o resultado do seu modelo. Existem outras técnicas de feature engineering além das abordadas aqui e o uso delas vai depender das características dos seus dados. Existem também alguns estudos para automatizar o processo de feature engineering a fim de reduzir o tempo de desenvolvimento de um projeto de aprendizado de máquina, bem como a necessidade de intervenção humana. Mas, enquanto esses estudos não se tornarem ferramentas, invista bastante tempo nessa etapa.
Software Engineer | Apaixonada por python e dados. Buscando soluções que possam tornar o mundo um pouco melhor. Fotógrafa e fã de futebol americano nas horas vagas.
FAQ Node.js: o que você precisa saber para fazer a escolha certa
Precisa de algo com foco em escalabilidade e diversidade? O Node.js é rápido, leve e poderoso. Se você quer explorá-lo para programar em JavaScript confira esse guia que preparamos sobre esse ambiente de programação e solucione todas as suas dúvidas sobre o tema! + leia mais

Animações em React Native
O mundo em que a gente vive é dinâmico. Mas, em muitos websites, várias interações são instantâneas e elementos somem e aparecem ou mudam de uma forma completamente artificial e nada convincente. Para melhorar essa experiência, nós, como desenvolvedores, precisamos usar animações, e, neste post, vamos ver algumas opções de como fazer isso em React Native. + leia mais




