
Análise exploratória para modelos de aprendizado de máquina

Bem, como modelos de aprendizado de máquina são baseados em dados, precisamos saber quais deles são realmente importantes, quais podem não fazer muita diferença e se algum está faltando para obtermos bons resultados em um modelo preditivo. Afinal, não se pode esperar uma previsão confiável quando não se tem dados consistentes. É como ensinar algo errado pro seu filho e esperar que ele acerte no futuro. Por isso é tão importante saber quais “informações” seu modelo precisa para acertar.
O que é uma análise exploratória?
Análise Exploratória de Dados (EDA - Exploratory Data Analysis) é o processo de investigar os dados com estatísticas e representações gráficas para melhor compreendê-los. Utilizamos técnicas para tratar valores ausentes que possam existir na base de dados, padronizar variáveis que não estão na mesma escala, identificar correlações entre elas e gerar estatísticas descritivas. A análise exploratória pode variar conforme o tipo de dados que temos.
Na análise estatística clássica, por exemplo, precisamos testar hipóteses já existentes sobre o problema. Mas, em projetos de Aprendizado de Máquina raramente já conhecemos o problema por completo e temos hipóteses sobre ele. Como o EDA possui uma abordagem mais holística em comparação com a análise clássica, nenhuma suposição antecipada é necessária, não há perda de informação e é possível obter mais insights porque todos os dados brutos estão disponíveis para serem analisados para então começar a criar hipóteses.
Por que usar análise exploratória?
Como já comentamos, é muito importante conhecer qual o real problema que precisa ser resolvido para que se tenha melhores resultados em um projeto de Aprendizado de Máquina - e até mesmo para entender se vale a pena passar pelo esforço de construir um modelo preditivo. Entender muito bem o uso final do seu modelo é fundamental, pois caso contrário seu time provavelmente vai errar nos passos e o resultado final pode passar longe do esperado. Se sua empresa não sabe muito bem qual problema está tentando atacar, talvez a análise de dados seja ideal.
Analisando os dados é possível extrair insights de negócios que podem não ter sido identificados previamente, detectar padrões, derrubar suposições, compreender as relações entre as variáveis, testar hipóteses (caso você já as tenha), bem como localizar algum possível viés nos seus dados. Todas essas percepções são usadas para entender se um modelo preditivo é viável ou até mesmo necessário, e caso seja, o EDA também ajuda na escolha de um modelo preditivo apropriado.
Entretanto, mesmo nos casos onde se conhece muito bem o problema a ser resolvido, o EDA vai te ajudar a encontrar erros e padrões que podem não ter sido identificados pelo time de negócios. Crie hipóteses a serem analisadas junto com a equipe, porém tenha cuidado com o viés de confirmação que pode existir, que ocorre quando a equipe presta mais atenção nos dados que confirmam uma teoria previamente existente.
Não dá pra tirar conclusões sobre os dados apenas coletando-os, é preciso analisá-los cuidadosamente. É preciso entender os dados se você quiser entender o modelo de Aprendizado de Máquina.
Quando usar?
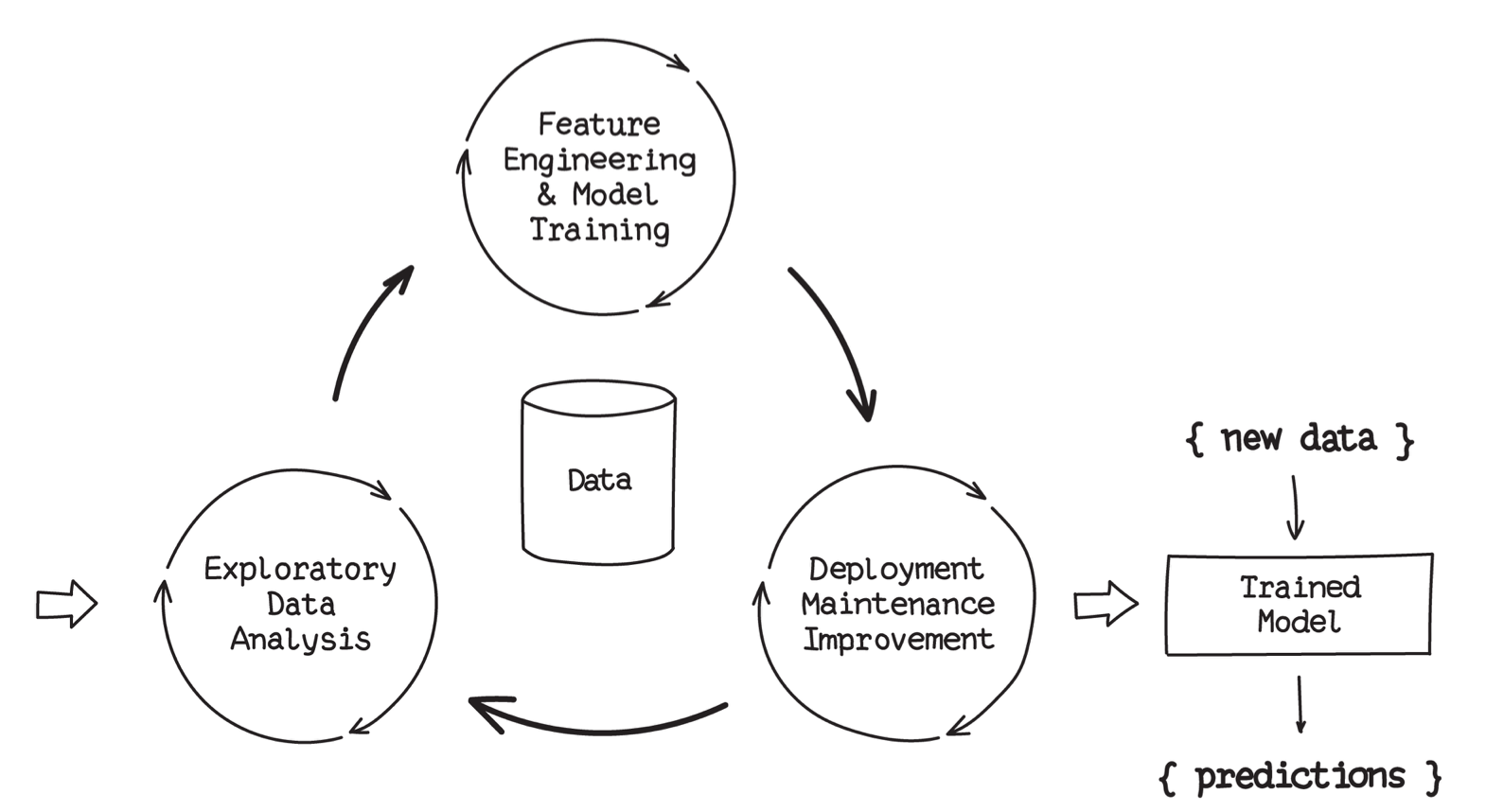
O EDA precisa ser o primeiro passo após coletar os dados, e também é aconselhável refazer esse processo constantemente, mantendo cíclica a relação entre análise e criação/melhoria do modelo.
O negócio é mutável, portanto os dados são mutáveis e certamente seu modelo não funcionará para sempre em produção. Por isso é importante fazer EDA para acompanhar as mudanças do negócio e seus efeitos no modelo. Algumas variáveis podem ter mudado o sentido, por exemplo, de uma variável que era positivamente correlacionada (quando duas variáveis se movem juntas) e mudou para negativamente correlacionada (quando as variáveis se movem em direções opostas). Portanto, não deixe de acompanhá-las ao longo do tempo.
 (Fonte)
(Fonte)
Tipos de análise exploratória
A análise exploratória de dados é realizada usando esses principais tipos:
Univariada não gráfica
Analisa apenas uma variável, onde o objetivo não é descobrir qual tem relações, e sim olhar para ela ao longo do tempo para tentar encontrar outliers e padrões.
Gráfico univariado
Temos uma representação visual dos dados e podemos ver algumas medidas estatísticas. Os tipos de gráficos mais comuns são Histogramas e Boxplots.
Multivariado não gráfico
Descreve a relação entre diversas variáveis a partir de estatística e tabulação cruzada.
Gráfico multivariado
Mostra a relação entre dois ou mais conjuntos de dados visualmente. O gráfico de barras é bastante usado para analisar um grupo de dados em função de outro grupo de dados. Geralmente esse tipo não é muito usado para conjuntos de dados pequenos. Outros gráficos bastante usados são o gráfico de mapa de calor e o gráfico de bolhas.
Exemplo com Python
Python é uma das linguagens de programação mais usadas para Data Science devido a frameworks que facilitam muito o trabalho de análise de dados como Pandas, Numpy, Seaborn, Matplotlib e Scikit.
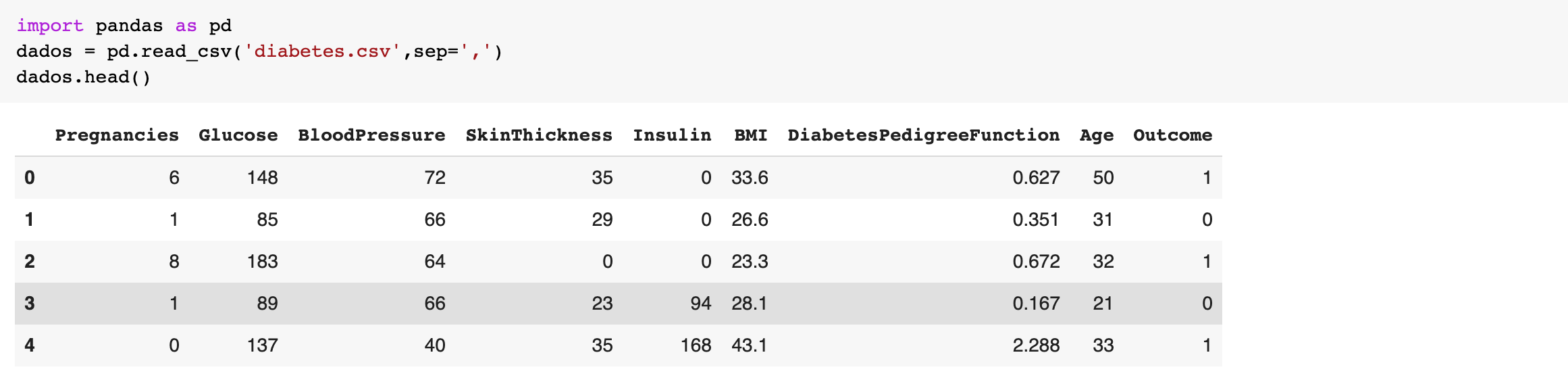
Vamos usar como exemplo uma base de dados que tenta prever se uma pessoa vai ou não ter diabetes fundamentada em algumas características. A base de dados original desse exemplo foi tirada do kaggle.
Com a biblioteca Pandas é possível ler um conjunto de dados em excel e transformá-lo em um dataframe com a função pd.read_csv.
Aqui apenas renomeamos as colunas.
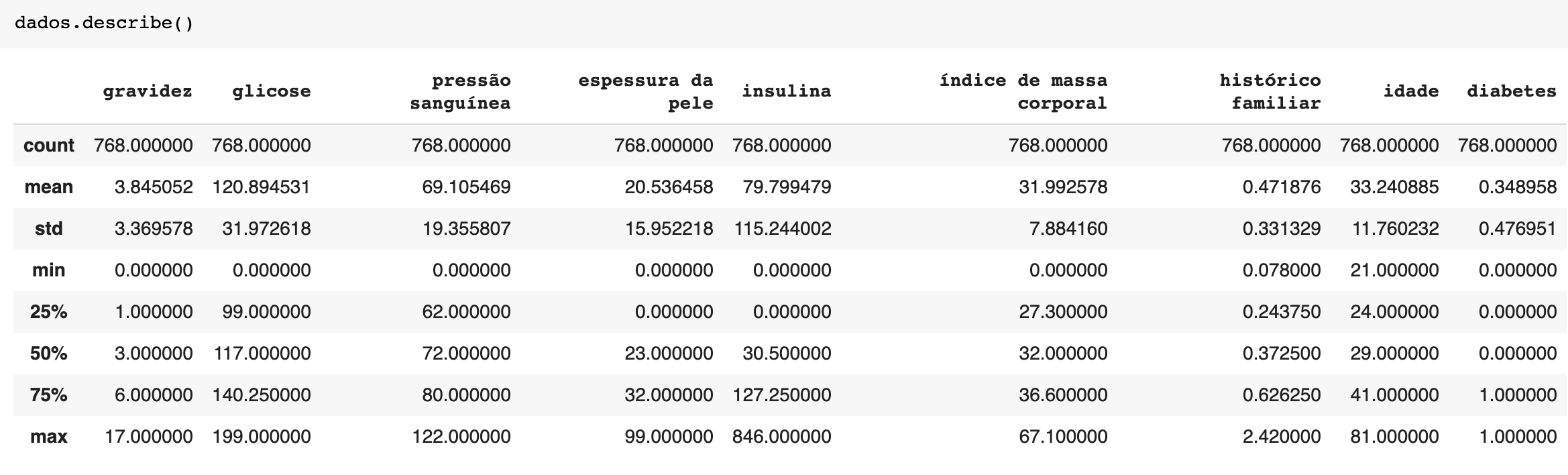
Após ler um dataset é possível usar a função describe() do Pandas para visualizar as métricas de estatística como média, desvio padrão, mediana e percentis que te darão uma ideia geral dos dados.
Novamente no Pandas, podemos usar a função corr() para encontrar a matriz de correlação entre as colunas, que mostra a correlação linear entre as variáveis, ou seja, quando uma cresce a outra cresce também. Porém, isso não significa que uma variável é a causa da outra. No nosso exemplo, a pressão sanguínea não tem uma alta correlação com diabetes, mas se tivesse, não indicaria que a pressão sanguínea é a causa da diabetes.
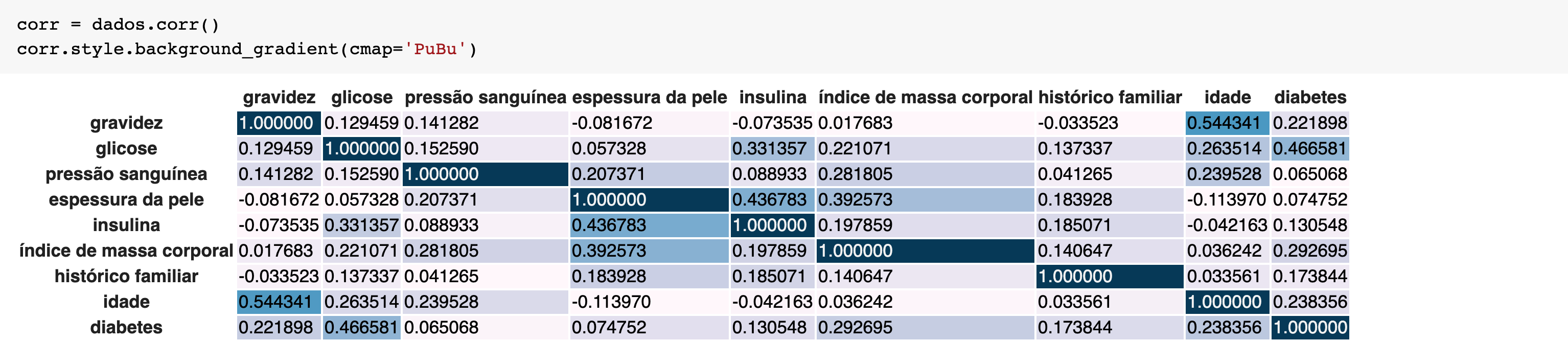
Lembrando que correlação não implica em causalidade.
Na maioria das vezes quanto maior for a correlação entre uma variável independente com a variável dependente que um modelo está tentando prever, mais importante ela se torna para o modelo. Variáveis com baixa correlação geralmente indicam que não tem grande influência na variável final que estamos tentando prever. A partir disso, podemos partir para o processo de escolher quais características dos dados são úteis para um modelo preditivo, bem como transformar essas variáveis quando necessário. Esse processo é conhecido como Feature Engineering, mas isso é assunto para um próximo post.
Valores ausentes podem ser um problema. Usando o comando dados.isnull().sum() é possível encontrar a soma de valores nulos em cada coluna.

Caso alguma delas tenha vários nulos, essa coluna talvez não seja um bom indicador para treinar um modelo.
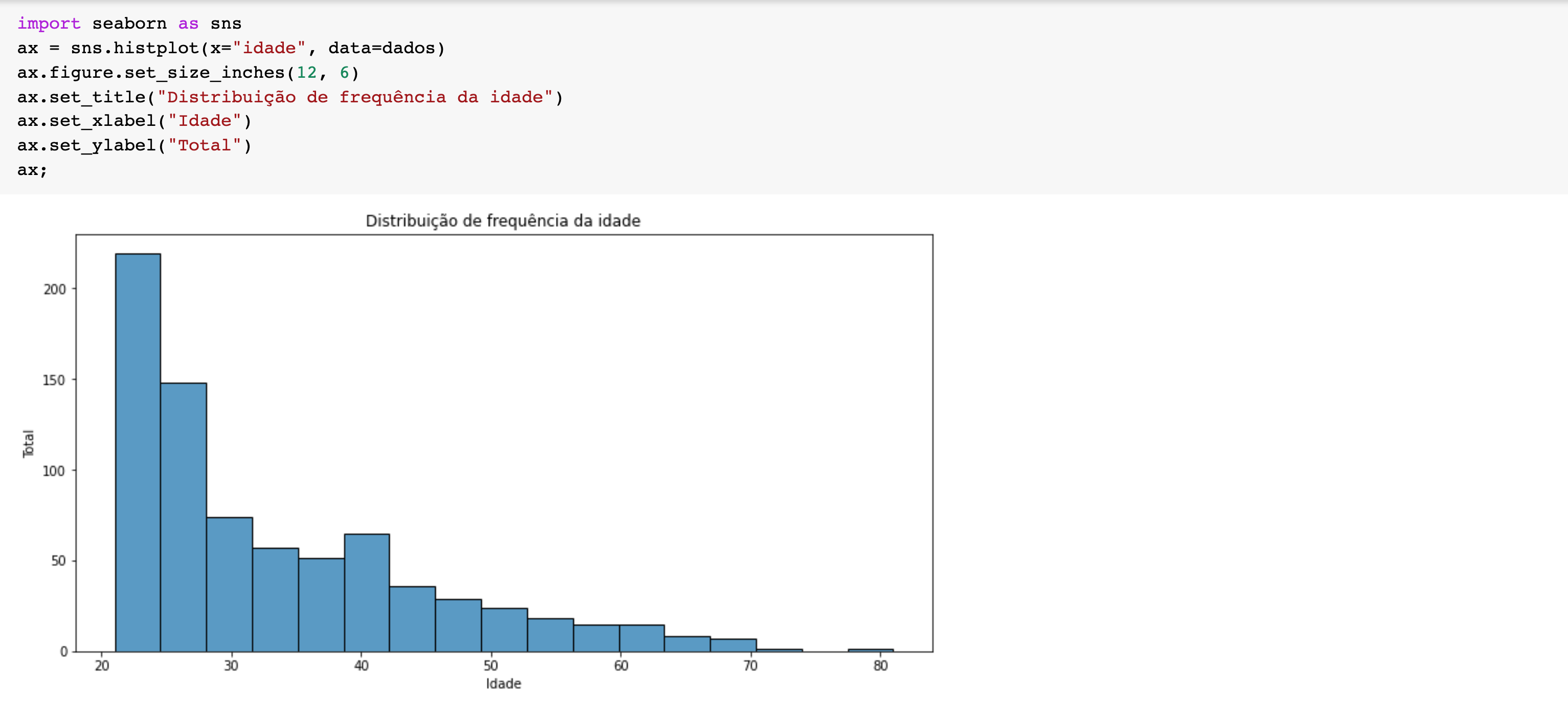
Os histogramas são gráficos onde podemos ver como é a curva de distribuição, nesse caso vemos que não é uma distribuição normal.
Os **boxplots **nos mostram como os dados estão distribuídos. A partir deles, conseguimos analisar alguns valores estatísticos visualmente. Podemos, com esse tipo de gráfico, identificar se os dados são simétricos ou não, e identificar a variação deles a partir da amplitude, por exemplo.
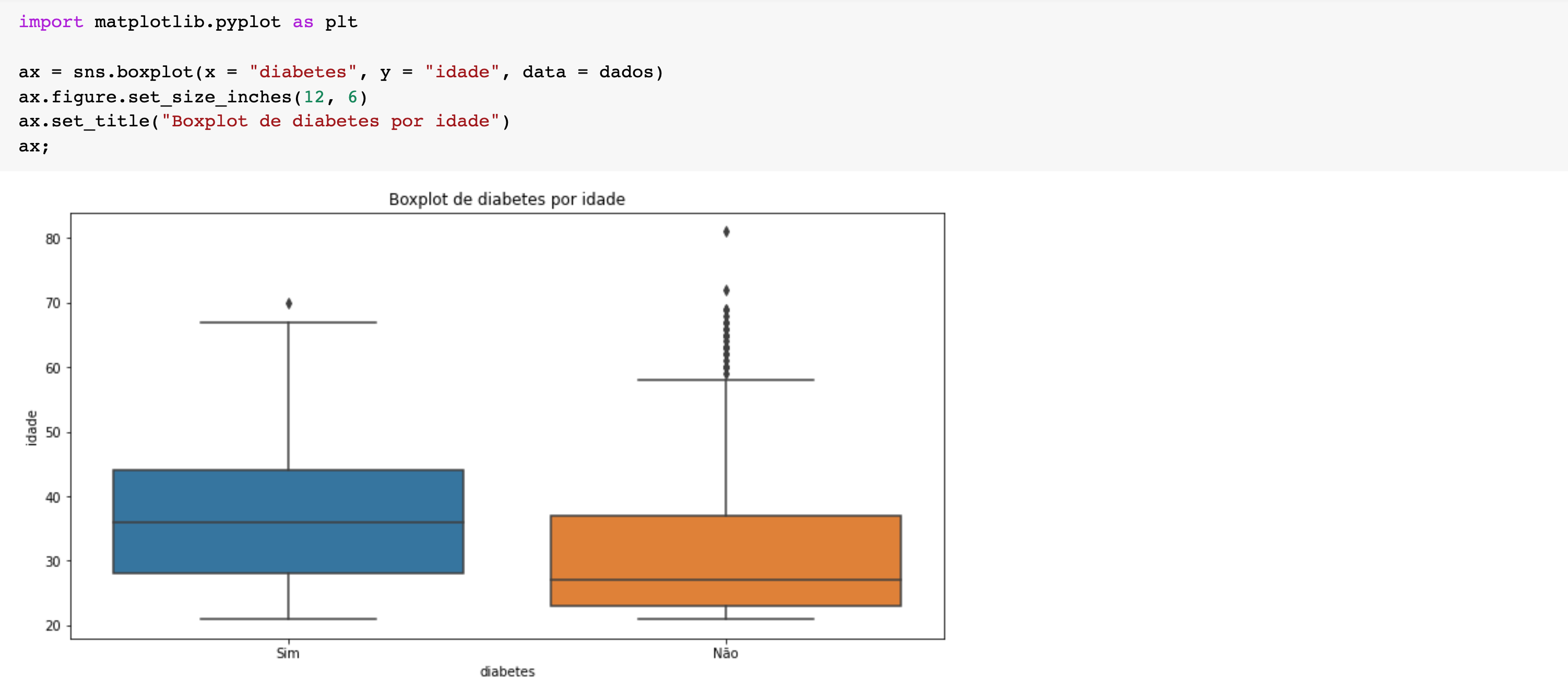
A primeira reta horizontal da caixa, de baixo para cima, representa o primeiro quartil da variável quantitativa (25% das observações possuem um valor abaixo do terceiro quartil); a última reta horizontal da caixa representa o terceiro quartil (75% das observações possuem um valor abaixo do terceiro quartil), e a reta do meio representa o segundo quartil (50% ou mediana). As retas acima e abaixo da caixa representam o máximo e o mínimo. E os pontos acima do máximo e abaixo do mínimo são os outliers (pontos fora da curva).
Olhando para os outliers podemos fazer perguntas como: Quais são os valores discrepantes? Por que eles ocorrem? Como eles podem afetar seu modelo?
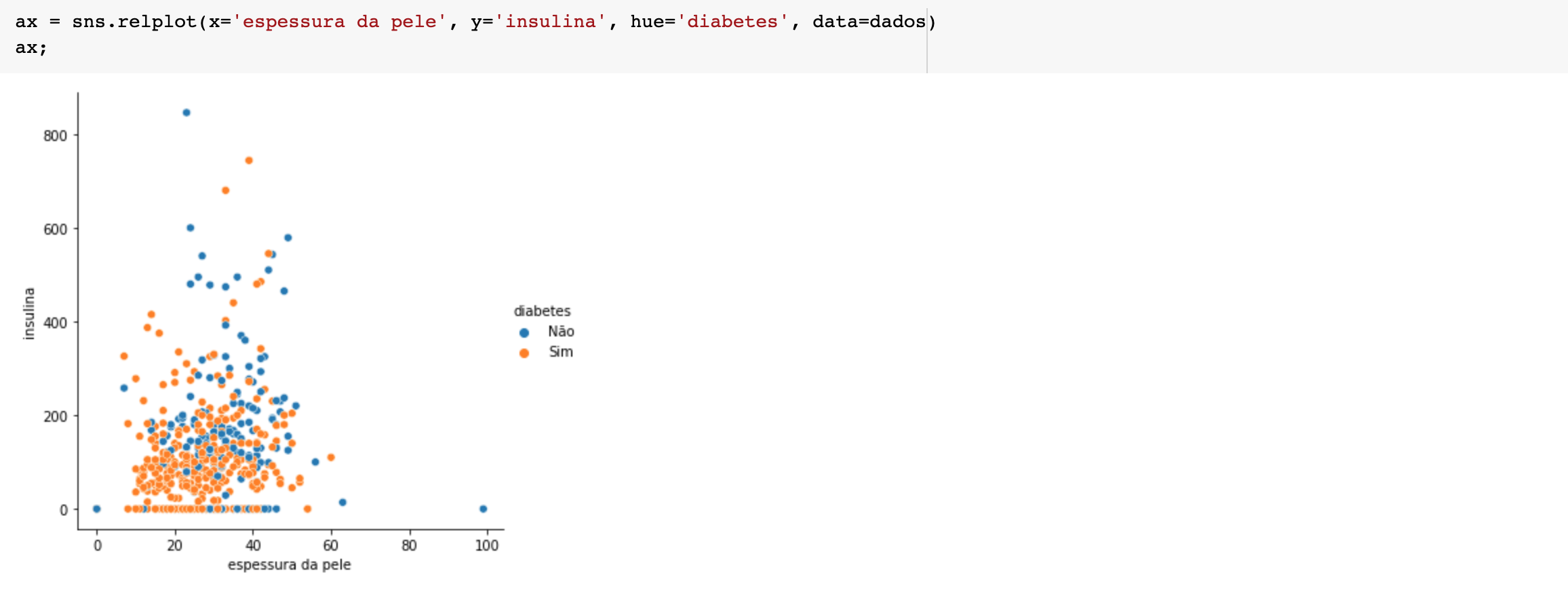
A criação de um gráfico de dispersão é uma maneira útil de encontrar relações entre duas variáveis, também para visualizar a correlação positiva ou negativa.
No gráfico abaixo podemos ver a relação entre insulina e espessura da pele tanto para pessoas com diabetes quanto para pessoas sem diabetes. Note que existe uma correlação de quanto menor a espessura da pele, menor a taxa de insulina no sangue em diabéticos.
Neste próximo gráfico temos alguns pontos bem fora do padrão. Temos também poucas pessoas com glicose abaixo de 70mg, o que indica hipoglicemia. Mas, não podemos dizer que quanto maior a idade maior a glicemia ou vice e versa. Não existe uma correlação forte e provavelmente não colocaríamos a idade como fator de influência quando uma máquina for prever se uma pessoa vai ou não ter diabetes.
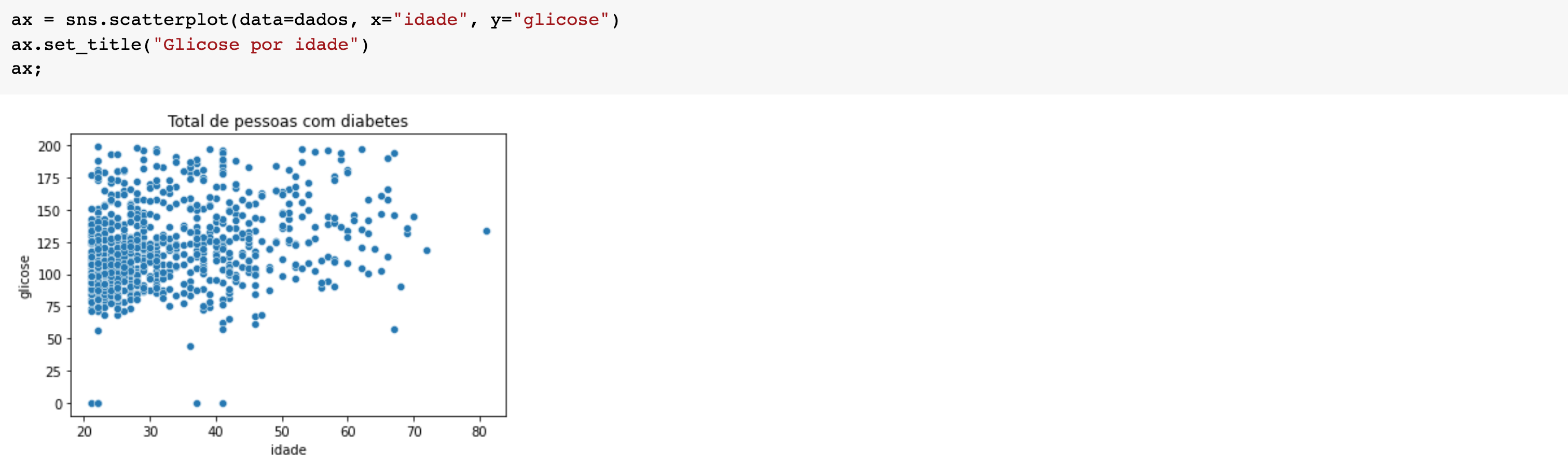
Usamos os gráficos como o histograma, boxplot e gráfico de dispersão para nos ajudar a reconhecer padrões e detectar outliers de uma maneira mais visual. Aqui, estamos explorando os dados, seja com gráficos ou com medidas estatísticas.
Conclusão
O EDA tem profunda importância no aprendizado de máquina. E é importante usá-lo durante todo o projeto, inclusive na manutenção dele para gerar modelos mais precisos e imparciais.
O entregável de um EDA geralmente é um relatório contendo as descobertas e recomendações da análise. Mas cuidado: lembre-se que o foco não é o relatório, e sim entender os dados e o problema. Muitas vezes o relatório pode até ser descartável, o que se mantém é a compreensão dos dados e do negócio. O foco da análise exploratória é entender o problema e se preparar para a próxima fase. Você não precisa necessariamente de métodos ou gráficos estatísticos avançados, se preocupe mais com as hipóteses que estão sendo criadas a partir dos dados.
Os modelos serão tão bons quanto as perguntas que você fizer, e de quão bom for o seu entendimento dos dados e do problema.
Software Engineer | Apaixonada por python e dados. Buscando soluções que possam tornar o mundo um pouco melhor. Fotógrafa e fã de futebol americano nas horas vagas.

Meeting machine learning types: supervised, and unsupervised methods
Machine learning allows us to find patterns in data and to generate predictions that can be used for various purposes. In this post, we cover machine learning concepts and talk about its types. + leia mais

Hands-on: classificação com KNN e K-means
KNN e K-means são algoritmos de aprendizado de máquina que permitem, respectivamente, classificar e clusterizar conjuntos de dados. Neste artigo, vamos colocar a mão na massa e identificar a categoria dos dados pertencentes ao conjunto Iris. + leia mais



