
How to scale applications with Elixir

In my latest article, I commented on several practices that are necessary in a system with minimal conditions to scale in production. Today, however, I will show you in a direct and practical way what types of measures you can take to scale applications with Elixir We'll talk about the examples shortly.
Notice, though, that 'scaling' is not a simple concept, as something would just 'succeed' or 'fail' to scale and that would be it. In practice, several factors influence the real 'scalability' of a system. Each system has different bottlenecks and needs. With this in mind, I will talk about a brief group of actions, which do not necessarily cover everything you need to scale in all situations, but will certainly help you increase the overall capacity of your application.
What you should NOT do to scale your system
Some of the most striking problems regarding performance, security and code robustness of your application come from things that have been done, and not from things that you didn't do in terms of development. So I decided to start with this group, because the most effective way to avoid bottlenecks in your system is to avoid committing any of the following atrocities:
Mistake #1 - Business logic within Controllers
This is probably the most common problem with code architecture, considering that Elixir has elements in its syntax that resemble those in Ruby. Note that the premise of Elixir / Phoenix **revolves around contexts, so it is extremely important that your business logic lies within those **contexts.
It is common for developers coming from Rails to try and 'Rubify' some logic and throw them directly in the controller, assuming that the Elixir code would have a more verbose aspect in relation to Ruby. In general, Elixir tends to have a little more boilerplate - those code structures that would not necessarily be mandatory in Rails or another framework. In Rails, for example, Active Record is already available from the beginning, without code. With Elixir, on the other hand, it is difficult to execute Repo functions without your own wrapper. The example below shows a user being obtained in Ruby to be rendered in a view:
@users = User.where(name: 'Carlos')
In Elixir, though, the most common solution involving contexts would be something like:
# assumindo que há list_users/0 e list_users/1, que recebe uma keyword list de atributos
users = MyApp.Accounts.list_users(name: 'Carlos')
A common mistake happens if the developer tried to 'bypass the context' by creating logic directly in the controller, which would make the controller code look like this:
defmodule MyAppWeb.UserController do
use MyAppWeb, :controller
import Ecto.Query, warn: false
alias MyApp.Accounts.User
alias MyApp.Repo
action_fallback MyAppWeb.FallbackController
def index(conn, %{} = params) do
permitted_params = permitted_filter_params(params)
users =
User
|> where(permitted_params)
|> Repo.all()
render(conn, 'index.json', users: users)
end
defp permitted_filter_params(%{} = params) do
params |> Map.take([:name, :email, :status])
end
end
Notice that although there is no longer a need for a context in this specific case, the import and alias the context did had to be transferred to the controller. The next step to 'continue without context' would be to create public functions in the schema file, something similar to what Ruby applications 'out of the box' usually do. From then on, the modularity and extensibility of code in your application would already be going downhill. So don't do it!
Always prefer to suppress all business logic to the context. In the controller, however, there are still things like filtering the allowed parameters, which is in fact the responsibility of a controller. Whether in a pipe with the collection of only the desired parameters, or through the filtering of parameters by the function headers, we strongly recommend doing something similar to avoid surprises when receiving calls from different clients that may come to access your API. Below, there is an example of what the recommended version of this controller would be:
defmodule MyAppWeb.UserController do
use MyAppWeb, :controller
alias MyApp.Accounts
action_fallback MyAppWeb.FallbackController
def index(conn, %{} = params) do
users =
params
|> permitted_filter_params()
|> Accounts.list_users()
render(conn, 'index.json', users: users)
end
defp permitted_filter_params(%{} = params) do
params |> Map.take([:name, :email, :status])
end
end
Use Elixir's system of modules as much and as coherently as you can. Remember, you can create sub-modules within sub-modules and so on. In practice it means that whenever a context becomes too large, you can create a subfolder with the name of the context, and within it sub-modules, each in its respective .ex file, in that old 'Context.SubContext' hierarchy .
An example of how to separate business logic into sub-modules if the 'Accounts' context ever grows too much:
MyApp
MyApp.Accounts
MyApp.Accounts.Configuration
Files
my_app/lib/
my_app/lib/accounts.ex
my_app/lib/accounts/configuration.ex
In this way, it is possible to segregate services (example: access to APIs) and more complex logic into smaller parts without compromising the modularity of your application, with the advantage that you're the one who defines the hierarchy according to the specific needs of your system.
This approach also facilitates automated tests, as each context has its own context_test.exs, where each test unit is segregated to the scope for which it is actually responsible.
Finally, it also facilitates Domain Driven Development. According to what the DDD guideline recommends, only (and all) the 'usable' logic a system contains must be mapped, and nothing more.
By not having, for example, a function that creates or deletes a user in a certain way, you guarantee that it is not a side effect in the universe of your system.
Therefore, for the safety and good level of isolation of your system, it is recommended for such side effects to be avoided whenever possible, which is usually in a tradeoff to the project's development and kickstart productivity, but almost always worth it against the latter in the short-medium term.
Mistake #2 - Filterings, Mappings, and other iterations involving Enum module
It is common, upon discovering how useful the functions from the Enum module are, that you want to filter data using the function Enum.filter / 2 to customize the result of what was obtained, for example, through a function list_something() within a context.
Given the level of language optimization - thanks to Elixir, Erlang and BEAM - functions like Enum.filter / 2 and Enum.map/2 usually run incredibly fast even for 10,000,000+ entries.
Even so, especially if the data to be iterated in general is very large, it is possible that the chain of iterations can compromise the performance of your application in a very intense way.
Below, a snippet of what could be considered an 'Enum hell' situation:
# ...
permitted_params
|> Enum.map(&MyApp.SomeUtilModule.function/1)
|> Enum.filter(&MyApp.SomeUtilModule.some_function/1)
|> Enum.map(&MyApp.SomeUtilModule.SomeDataConvertingModule.some_other_one/1)
|> Enum.sort(&MyApp.Oh.my_god/1)
# ...
It is recommended, therefore, to avoid iterating in excess in this way, and if necessary, transfer filtering and sorting logic to the Context, doing what is possible in terms of processing through Repo and Ecto Queries.
Another tip is, if you need to make mappings, try to make them in lists already paginated by your application's pagination scheme. That way, you will always have to iterate over a much smaller mass of data.
Mistake #3 - On-Premise Deploy
Currently, most cloud services have affordable prices in terms of infrastructure costs, and given how broad the benefits are - and more importantly, the absence or mitigation of certain risks - it is unlikely that on-premise infrastructure, which consists of specific physical machines that you or your company have control over, would be more suitable than an infrastructure entirely in the cloud.
The reasons to prefer cloud solutions over on-premises are numerous, like automatic and self-managed backups, scalable hardware infrastructure with the sliding of a few options, among others. Not to mention that, at least in the foreseeable future, data can always be considered as safe or more secure in the cloud than on-premise, where only your team would care for the integrity and security of the infrastructure and therefore, the chance committing a small slip or mistake that exposes a fault tends to be greater.
In addition, in the on-premise situation, the deployment process tends to depend much more on automations that your team will have to build, considering if it ever gets automated, than on pre-existing and consolidated tools on the market.
What TO DO to scale in terms of code:
1. Umbrella applications (when reasonable)
Over time the creation of modules, different APIs, versions of APIs, among other elements in your system can get immense. Furthermore, you'll most likely not want to mix your controllers with your domain.
That's where Umbrella applications come in. Through them, you already start by generating an initial separation between your domain and server in a simple, methodical and organized way by default. In addition, if necessary, it is possible to deploy each of them separately and even on different machines.
An important note: if it becomes necessary to use different configurations in each application for the same dependency, or to use different versions of dependencies by applications, for example, your code between applications is probably different enough that you need to have separate projects (different services), not just an Umbrella project.
Escaping, for example, from the Mono-Repo standard that Umbrella suggests means having to deal with a great business logic for controlling entities. In this specific example, the system has possibly got way through what would be considered healthy for a monolithic application.
For more information about Umbrella projects, some references:
2. Use pagination techniques
It is supposed that when talking about scaling a system, we count on a large number of users, posts, messages, accounts, or any other entities that an application has.
Therefore, it is impossible to expect requests on your system to pass through in a way that any of your API endpoints, which can be json, html, or others, would bring all the records in the simple way that you work with users = Accounts.list users( ), followed by a render of all those users.
If it happens in a system that has any generous number of users, that response will either never arrive, or it will take so long and consume so much processing power that your system will have a poor resource conversion rate.
Whether via Paginator, Scrivener, Websockets or any other method, you must manage that the answer that reaches your client is always a slice of something that can be served in a timely manner, which is, paginated, as the client needs and is able to receive.
As a side note, even your own front-end will need to be able to handle the paginated response, as a huge, untreated listing in your .html.ex file will likely suffer from the same consequence.
3. Use strategies to transit less data
Flowing only the important data is always vital when scaling a system, since it basically represents resources saving and therefore with the same finite number of resources, your system can handle more requests, in less time.
In this regard, any method is valid. The first and most basic is gzip compression (or similar ones, like Brotli), which in Elixir and Phoenix can be enabled in just a few lines of code.
To enable gzip compression on all of your static assets, edit your lib / my_app_web / endpoint.ex, and change the **gzip parameter from false to true**:
plug Plug.Static,
at: '/',
from: :my_app_web,
gzip: true,
only: ~w(css fonts images js) # + outros
To also compress all the bodies of requests from your server, you can add this configuration to your config / prod / secrets.exs:
config :my_app_web, MyAppWeb.Endpoint,
http: [port: {:system, 'PORT'}, compress: true]
# ... outras configurações que seu server possa ter
There are several (yet very effective) other methods in addition to what could be covered in detail in a single article, such as data traffic outside conventional HTTP REST calls. Nevertheless, we'll address their existence shortly:
In GraphQL, it is possible to filter what you want to obtain in a response - ie. when displaying a user's registration data - to return only what is pertinent to the desired requests. It may not seem as effective, but in some situations it is the difference between having or not a performance bottleneck.
Other techniques, such as the use of RPC libraries, such as gRPC, allow communication via RPC, which, despite traveling on the network as an HTTP 2 call, allows the interface of several RPC communication media in a multiplatform way.
Via RPC, your client or front-end and your server can communicate via function calls already known to each other, and in this way, the data transferred can be reduced to only what is strictly necessary.
4. Non-sequential IDs
This tip is not so much related to improving the performance of the system, and in some cases what happens is a little bit the opposite. Using non-sequential strings, such as UUIDv4, in the past has even brought performance problems to databases.
Currently, performance differences, although existent, tend to be insignificant in most cases in relation to the use of the common sequential ID. Data that is contained in relational tables like PostgreSQL - but has so many rows that can cause notable performance problems with UUID (10M +) - should probably not be in a relational database, anyway, but in some big data storage.
But, why use non-sequential IDs? What are the advantages?
The first advantage is that it adds a light (but extra) layer of security to your server. By not having the identifier of your resources with any predictable value, you don't give away to the client details of your internal operation, such as number of users, number of administrators, number of posts, number of credentials or any other resources. Your customers will never know if they were the tenth to be created when their id is something like '2c9695b7-f899-4849-9d20-203a65e44474'.
Through UUID, additional protection against non-authorized access to resources is also gained. **Although this should never be your only security measure - there must be a real permissioning mechanism that takes care to validate whether a certain user or client has the right to view / interact with certain data **- this additional measure can act as a fallback layer of security and save your skin in case of an 'authorization mess-up', acting as a last barrier in case of improper permissions being given.
In case your system is distributed, as a multi-shard DB for example, it is even possible to gain performance using UUIDs, as they allow several points in your system to insert records in the same base without contact with each other, even if it is physically stored in different locations. In this way, each of these nodes can store generated UUIDs without the need for a sequence when changing these values over each insertion, requiring no extra coordination or overhead to manage such inserts.
It is worth mentioning that you do not need to apply UUID in every entity of your system, but only to those that need the features UUID offers - in most cases, those whose IDs the user or client of your API will need to use to interact.
Remember, though, that IDs were made for developers and machines, while slugs were made for people. If an end user has to interact with a resource by passing an ID, it is likely that in this case it would be better to use a unique slug, which is a string that identifies that resource in a user-friendly way.
To use UUIDv4 by default in applications with Elixir, you'll need to follow the following steps:
Modify the schema generators to generate the UUID boilerplate by default, in your general config file ./config/config.exs:
# ./config/config.exs
config :my_app,
ecto_repos: [MyApp.Repo],
generators: [binary_id: true]
From then on, all models generated by Phoenix scaffolds will have the following format, which tells Phoenix that that schema must be referenced using UUIDs. Below is an example of a schema after it has been generated or modified to the** UUID-enabled format**:
#./lib/my_app/my_context/my_entity.ex
@primary_key {:id, :binary_id, autogenerate: true}
@foreign_key_type :binary_id
schema 'my_entities' do
# ...
end
For migrations, however, it is necessary that each entity migration that will have the primary key as UUID always remains in the format below, which says that its id has the type binary_id (a string). Like below:
def change do
create table(:users, primary_key: false) do
add :id, :binary_id, primary_key: true
timestamps()
end
end
From there, your entity will be ready to use and be referenced through its non-incremental id.
5. Delegate complex calculations
Despite all efforts, some tasks are just too heavy for a single system to deal with alone. Some conversions, such as video files, may become too much for your monolithic application.
In these cases,** try to create separate services whenever you need to, but without necessarily having to adopt any stellar architecture with dozens of microservices or anything like that**. The idea here is to balance load without flooding your system of complexity.
Whenever a task is more intensive and constantly demanded, export it to a service, like some smaller application, even in other languages like node.js - node.js and express servers for microservices are very common. Or, even more scalable, to some serverless function (example: Lambda on AWS, GCF on Google, among others). Through serverless functions, no matter how many simultaneous requests your service receives, a new instance of the function will appear to do the job.
What TO DO to scale in terms of Infrastructure:
1. Asynchronous tasks
As I mentioned in a previous article (still in PT-BR, but to be translated), it is crucial that almost any relevant web system has, when going into production, some mechanism for handling asynchronous tasks and jobs.
Your server should not stop being able to respond until a welcome email is triggered, for example, or until a certain integration is processed after your users' onboarding process.
As a good criteria, any non-instantaneous operation that can be left for an asynchronous time should be postponed. This shifts your processing time to when your system can handle it. That way, you fill in time that would be considered idle time by doing relevant processing, which has been released from the times of need they were originally in.
There are several tools in applications with Elixir that can be used to manage asynchronous processing, such as ** Exq + Redis** and others. Elixir's own OTP and GenServer architectures allow your system to manage asynchronous tasks even without additional libraries.
2. Cache, APM, CDN, WAF & others
This list includes tools that may be required in some (or several) circumstances while scaling your system. As it would be impossible to talk about every one of them in detail in just one article, and given they are all available as SaaS services on cloud service platforms, I will quickly pass through each one of them:
Cache - It may be recommended especially if the system needs fast or repetitive access to certain data that may take a long time to obtain. In-memory caches like redis and memcached are available on all cloud platforms as ready-to-go services.
**APM **- Application Performance Monitoring is also available on several SaaS services out there, such as Data Dog, Elastic APM or New Relic, and they might help you point out various performance bottlenecks throughout your system. You can monitor endpoints where requests take longer, generate detailed errors, create alerts for certain system stress situations and manage several customizable events, among other features that can help you optimize (a lot) your system.
CDN - Content Delivery Networks can be extremely useful when it comes to scaling your system, especially when it comes to serving content (assets, videos, images) quickly on a global scale. Hiring a CDN service allows you to install points of presence (PoPs) in different areas where your company operates, allowing your content to reach the end user much faster.
WAF - Web Application Firewalls help making your application more secure and less susceptible to interaction with clients with malicious intentions.
Events such as DDoS attacks, automated creations with the objective of creating spam or exploiting flaws within the system, among other attacks will almost certainly happen to your production scaled system if there is no security measure in place.
Through a WAF - which can be hired by services like CloudFlare, Google Cloud, AWS, among others - you can define policies that define what is a 'legitimate' request and what should be blocked, making your application much more resilient.
3. Vertical Scaling (machine power scaling)
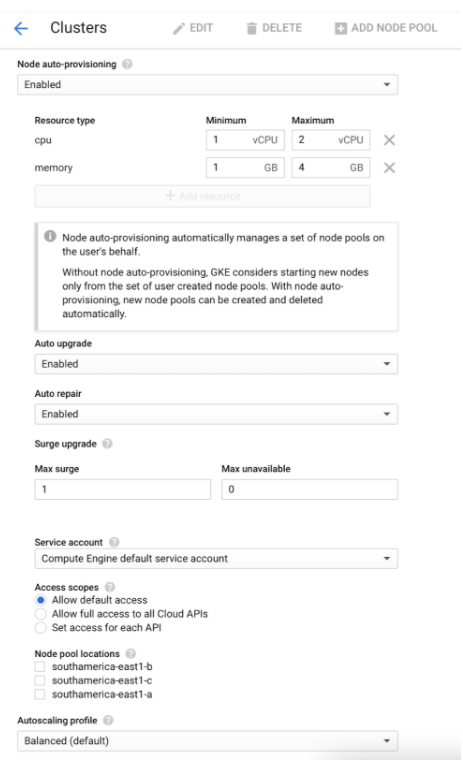
Vertical scaling means, in its core, scaling the amount of sheer power your server machine has. In most cloud services, though, it is usually obtained via dynamically scaling the number of vCPUs that compose your server machine's processing power.
In topologies like Kubernetes, for example, you can configure the vertical auto-scaling and processing power settings of these nodes dynamically, by editing the cluster settings, as in the image below:
4 - Horizontal Scaling
Horizontal Scaling, on the other hand, involves expanding the instances of your system regardless of its physical machines' power. This can be done by either increasing the number of physical or virtual nodes **with instances of your server (usually helped by a load balancer), **or also by increasing the number of containers (or pods or other nomenclature) that will spawn as replicas to have your server listening in more instances at the same time.
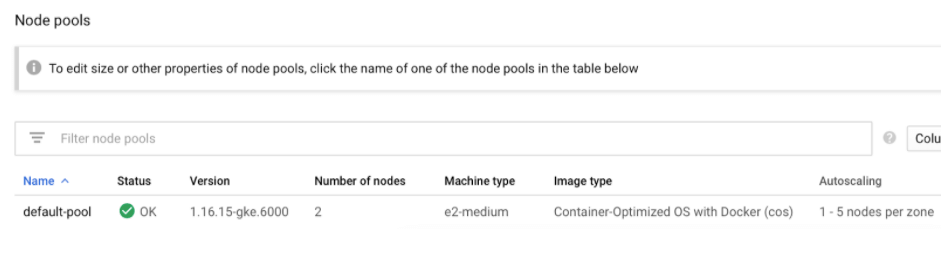
In Kubernetes, basic Horizontal Scaling can be done by configuring the 'autoscaling' part of your Cluster's node pools, like below, where a cluster pool has been configured to oscillate between 1-5 nodes:
Kubernetes itself also has a separate service known as HPA: Horizontal Pod Autoscaler. This type of service changes the structure and number of replicas of your application's pods in response to a constant measurement of CPU and memory consumption, or in response to custom metrics processed within Kubernetes.
It is possible to configure the Horizontal Pod Autoscaler in GKE (Google Kubernetes Engine) according to the metric you need in your deployment in a few steps, by following this documentation.
Conclusion
We saw in the course of this article that when it comes to scaling an application, there is really no recipe: the care fronts necessary to provide scalability in a given system are in fact many.
Thus, it is important not only to verify that a fixed checklist of optimizations is being fulfilled, but to always observe critically for possible sub-optimizations and performance bottlenecks, so that you and your team take the right measures about what your product needs to climb at that moment.
Finally, I hope I helped you create more scalable Elixir systems. See you in the next article!
Software Engineer | Fascinado por tudo que envolve ciência, lógica e conhecimento. Criptografia, user interfaces, eletrônica digital, Internet das Coisas. Fã de código limpo e reutilizável.

Busca de dados em React, além do básico
Um dos grandes desafios na construção de uma aplicação em React é determinar um padrão de código para buscar dados de um servidor. Vamos ver algumas opções neste post. + leia mais

Como escalar aplicações em Elixir
Cada sistema em produção tem suas particularidades. Por isso, existem diversas maneiras de escalar aplicações em Elixir. Embora não exista uma receita de bolo, neste artigo, você encontra um grupo resumido de ações que irão te ajudar a aumentar a capacidade geral do seu produto digital. + leia mais



